
A Privacy Professional’s Guide to Generative AI: Between a Rock and a Hard Place

A Privacy Professional’s Guide to Generative AI: Between a Rock and a Hard Place
The rise of Generative AI presents an unprecedented challenge for privacy professionals. Unlike previous technological advances, it doesn’t just push the boundaries of our existing privacy frameworks – it fundamentally challenges their core assumptions.
As a privacy professional who has weathered numerous technological storms, I can say with certainty: Generative AI is different. It’s not just another challenge, it is a paradigm shift that forces us to reimagine our entire approach to data protection. In this article, I explore these challenges and possible approaches to navigate the complexity.
The Privacy Paradox
Let’s start with an uncomfortable truth: Generative AI, in its current form, seems almost deliberately designed to challenge every fundamental principle of data protection. At the heart of this issue lies the fundamental challenge of establishing appropriate legal grounds for AI systems.
- Legal Basis for Processing: Determining whether explicit consent is required for training Large Language Models (LLMs) or whether legitimate interest suffices remains a thorny issue. Should different lawful bases apply to distinct AI development stages (e.g., data collection, training, deployment) and various use cases (e.g., public chatbot services or personalized marketing)?
- Regulatory Guidance: The European Data Protection Board (EDPB) is drafting an opinion on applying GDPR to AI models. This guidance, expected in late December 2024, promises to provide clarity on these questions.
Hannah Ruschemeier’s recent analysis highlights key tensions between Generative AI and privacy laws:
- Data Volume vs Individual Control: The quantity of the data processed from various sources seems to make it impossible to identify and inform individuals of the processing, or of the processor, to enable data subjects to assert their rights.
- Rights Enforcement Challenge: Beyond the sheer scale of data processing, the universal nature of LLMs creates unique complications for individual rights. LLMs and other generative AI models that produce content operate almost universally, not just at an individual level. This creates a significant mismatch between data-intensive models and an individual rights-based approach to data protection
- Purpose Limitation Conflict: Data protection is highly contextual, and its level of protection depends on the type of data processed, by whom, in which settings, and for which purpose. LLMs on the other hand, cover a wide range of purposes, applications, and operating environments.
The complexity is enough to make any privacy professional to reach for the aspirin.
Emerging Privacy Issues
- Inference Capabilities: It is well demonstrated that generative AI models are able to infer personal attributes of data subjects from large collections of unstructured text (e.g. public forum or social network posts) with high accuracy. The privacy concern arises from the fact that this new data generated by making inferences can reveal personal information that either has not been disclosed by the individual or is inaccurately attributed to the individual.
- Algorithmic Discrimination: While algorithmic bias is often framed as an ethics issue, it has significant data protection implications. Algorithms that can perpetuate and amplify biases about fairness, discrimination, and the potential harm caused by biased AI-generated content. Examples include models that display negative sentiment towards social groups, link occupations to gender or express bias regarding specific religions.
- Information Integrity: As AI-generated content becomes more sophisticated and financially rewarding, we face a future where truth becomes increasingly subjective and verification increasingly challenging. A recent case in Spain perfectly illustrates this: when devastating floods hit Valencia, legitimate photographic evidence was considered as “AI fake” – precisely because of its dramatic authenticity. This phenomenon signals a shift in our collective ability to distinguish truth from fiction.
- Security Vulnerabilities: Research by Gupta et al. illuminates various techniques that can compromise LLMs security safeguards. These include jailbreaking, where specific prompts bypass built-in restrictions; reverse psychology, which manipulates the model through indirect questioning; and prompt injection, which extracts sensitive information through carefully crafted inputs. These vulnerabilities underscore the need for robust safeguards to protect against misuse.
The chart below highlights the various types of attacks performed on Generative AI.
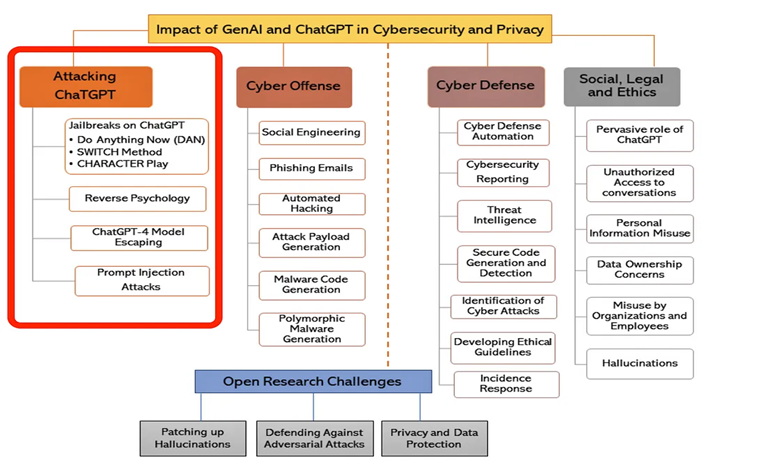
From IEEE paper by Gupta, Akiri, Aryal, Parker, Praharaj
From Nightmare to Opportunity
Instead of seeing Generative AI as privacy’s nemesis, what if we view it as a catalyst for evolution?
This technology is pushing us to:
- Enhance Privacy Engineering efforts:
Organizations must prioritize and significantly scale up their privacy engineering initiatives, particularly in the development and deployment of LLMs.
By embedding robust privacy engineering practices, such as differential privacy’s mathematical framework that introduces calibrated noise during training – organizations can create a foundation for responsible AI development that balances innovation with privacy protection.
Combined with advanced privacy-enhancing technologies such as federated learning, homomorphic encryption, model distillation, and adversarial training, one creates a sophisticated defense ecosystem that not only satisfies regulatory requirements but also builds trust with users and provides organisations with a competitive edge and market differentiator.
This strategic focus on privacy engineering goes hand in hand with comprehensive workforce development, including specialized training programs, dedicated privacy engineering teams, and organization-wide education on privacy-preserving techniques.
- Organisational Efforts:
Technical solutions alone aren’t sufficient – they must be integrated into a comprehensive organizational approach. Organizations must implement a multi-layered approach.
This starts with Privacy-by-Design architecture that embeds protection mechanisms throughout the AI lifecycle, supported by stringent ethical data sourcing protocols that ensure transparent and fair data collection. It is highly recommended that organizations establish and enforce clear guidelines for data collection, ensuring transparency, consent, and fairness in their data acquisition practices.
Standardized data pooling protocols can help organizations maintain consistency in data handling while enabling effective collaboration and model training.
Regular privacy audits to assess compliance, identify vulnerabilities, and measure effectiveness of privacy measures are critical to assess the effectiveness of the controls implemented.
By integrating these approaches, organizations can build a resilient privacy framework that adapts to the evolving challenges of generative AI while maintaining trust and compliance.
- Evolve our Regulations:
A slightly more controversial suggestion, proposing an evolution of the GDPR. Article 9 of the GDPR currently hinders commercial AI development by imposing requirements on data that could reveal sensitive characteristics. Unlike Article 6’s flexibility, Article 9 lacks practical exemptions for business applications, with research exemptions limited to academic work.
I propose a new Article 9 exemption for commercial Generative AI that would permit development under specific safeguards, including privacy impact assessments and clear data usage boundaries. Companies would need to implement privacy-preserving techniques, conduct regular audits, and maintain transparency. This targeted approach would establish compliance thresholds and oversight mechanisms, balancing innovation with privacy protection.
Final Thoughts
Generative AI is quite literally a game-changer, one that challenges the principles of data protection while offering unprecedented opportunities for innovation. By adopting a forward-thinking approach to privacy engineering, organizational practices, and regulatory evolution, we can transform these challenges into a sustainable future where privacy and progress coexist.
Looking to read more?
Creating trustworthy and secure AI systems is a complex challenge that requires a multidisciplinary approach. Recognizing this, we have formed a collaboration that we refer to as the “Golden Triangle”, consisting of an anonymization expert (Renate van Kempen), a cybersecurity expert (Anna Hakkers, PhD) and myself as a data protection expert. Each corner of the triangle: data protection, cybersecurity and anonymization, represents a critical domain of expertise that contributes to the overall integrity and security of AI systems.
Together, we are excited to announce a forthcoming series of articles, where each of us will provide our unique insights from three distinct angles on the same critical topics. We invite you to follow our series and join us in exploring these essential aspects of AI.
Leave a Reply